
AIの進化は早すぎると感じるかもしれません。しかし、2026年現在の「音声合成(TTS: Text-to-Speech)」の進化は、単なるスピードアップではありません。「読み上げソフト」から「デジタル俳優」への完全な変態(メタモルフォーゼ)です。

この記事では、Googleが提供する最新の音声モデル「Gemini TTS」について、公式サイトの奥深くに眠る仕様から、現場のエンジニアしか知らない回避テクニックまで、その全てを包み隠さず解説します。

音声のみはこちら↓
第1章:なぜ「Gemini TTS」は別次元なのか?
これまでのAI音声(WaveNetなど)と、Gemini TTS(Audio-LMベース)には決定的な違いがあります。それは「テキストの意味を理解しているか否か」です。
1. 「文脈」を読む力が生む”演技”
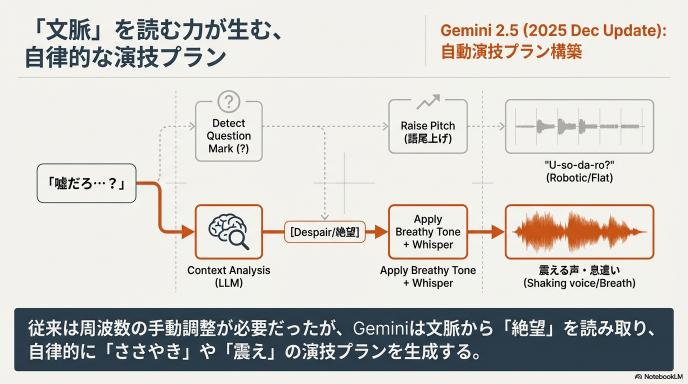
従来のTTSは、辞書にあるアクセント情報に従って音を出していました。しかしGemini TTSは、大規模言語モデル(LLM)そのものがベースになっています。
つまり、「テキストに書かれていない感情」を読み取ります。
- 例: 「嘘だろ…?」というテキストを入力した時。
- 従来: 「う・そ・だ・ろ・?」と平坦に疑問形で読む。
- Gemini TTS: 文脈が絶望的なら、息を漏らし、震える声でささやくように発音する。
2025年12月の「Gemini 2.5」アップデートにより、この演技力はさらに強化されました。ユーザーが細かい周波数をいじらなくても、「悲しそうに」と指示するだけで、AIが自律的に演技プランを組み立てます。
2. 「32,000トークン」の巨大な記憶
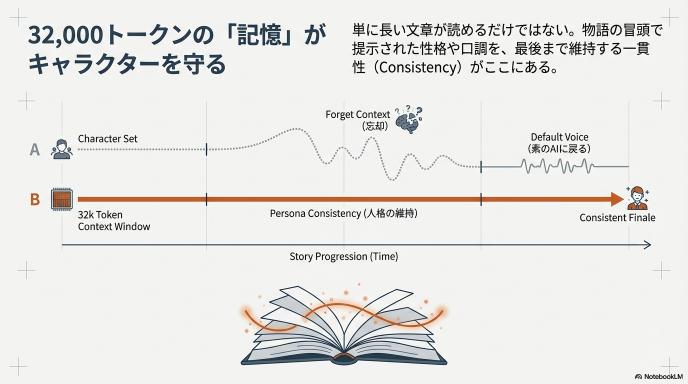
Gemini TTS(API版)は、セッションあたり最大32,000トークンのコンテキストウィンドウ(記憶容量)を持っています。これは、単に長い文章を読めるという意味ではありません。
「物語の最初の方で提示されたキャラクターの性格を、最後まで維持できる」ということです。長い朗読でも、途中でキャラがブレたり、急に口調が変わったりすることがありません。
第2章:3つの入り口と「選び方」のフローチャート
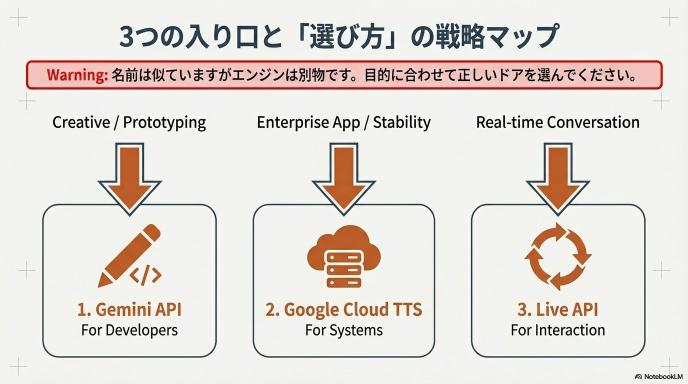
「Gemini TTSを使いたい」と思った時、Googleは3つの入り口を用意しています。これらは名前が似ていますが、中身は別物です。間違った扉を開けると、作りたいものが作れません。
1. Gemini API(Google AI for Developers)

- ターゲット: クリエイター、プロトタイプ開発、演出にこだわる人
- 最大の特徴:「自然言語プロンプト」が使える。
- 「おじいちゃんのような声で」「ニュースキャスターのようにキビキビと」といった指示が通じます。
- モデル名:
gemini-2.5-flash-preview-tts/gemini-2.5-pro-preview-tts - メリット: とにかく手軽。Webブラウザ(AI Studio)上で今すぐ試せる。
- デメリット: 大規模な商用アプリのインフラ(SLA等)としては、次のCloud版に劣る場合がある。
2. Google Cloud Text-to-Speech(Gemini-TTS)
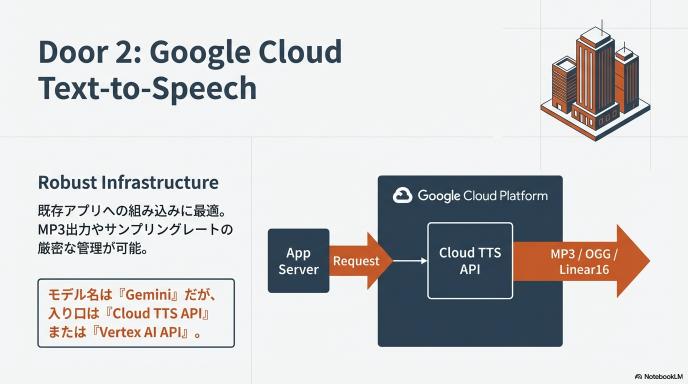
- ターゲット: アプリ開発者、企業システム、安定運用したい人
- 最大の特徴:Google Cloud基盤での堅牢な運用。
- 既存のアプリに組み込むならこちらが本命です。
- 注意点(モデル): API版と同じ「Gemini」という名前がついていますが、こちらは「Cloud TTS API」または「Vertex AI API」を通じて呼び出します。
- メリット: MP3形式での出力や、サンプリングレートの細かい指定が可能。
3. Live API(Multimodal Live)
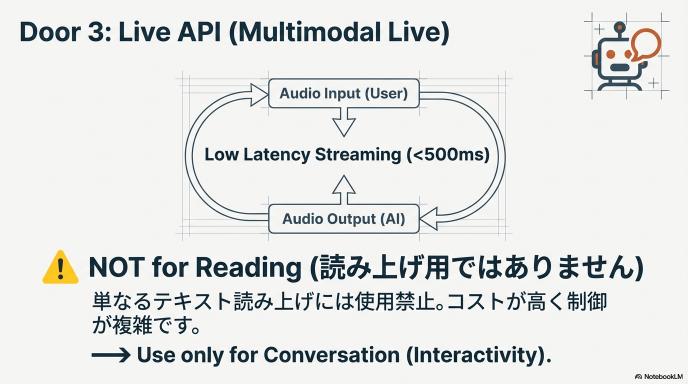
- ターゲット: 英会話アプリ、対話型ロボットを作る人
- 最大の特徴:「読み上げ」ではなく「会話」。
- これはTTS単体ではありません。音声を入力して、超低遅延で音声が返ってくる「双方向ストリーミング」専用のAPIです。
- ただ文章を読ませたいだけなら、これを選んではいけません(コストが高く、制御が難しい)。
第3章:【技術編】開発者がハマる「4つの落とし穴」と回避策
ここからは、実際に使おうとした時に必ずぶつかる壁と、その抜け道を解説します。
落とし穴①:音声ファイル形式の「Vertex AIの罠」
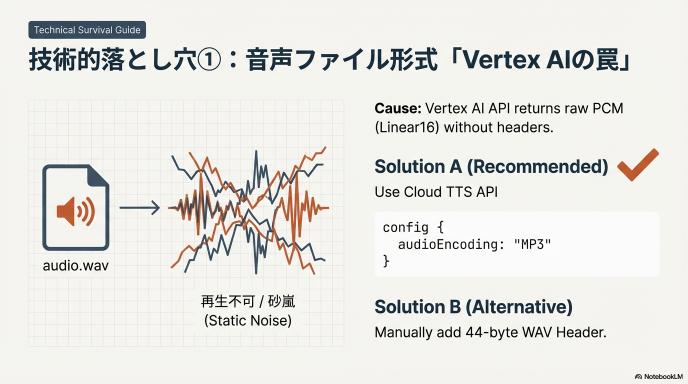
Cloud版を使う際、ルートが2つあります。「Cloud TTS API」と「Vertex AI API」です。
もしあなたが「Vertex AI API」経由でTTSを叩くと、返ってくる音声データは「PCM (Linear16)」という形式になることが多いです。
- 何が起きる?: 保存したファイルを再生しようとしても、「再生できません」とエラーになるか、ザザザッという砂嵐のようなノイズが流れます。
- 原因: PCMは「生の音データ」であり、MP3やWAVのような「ヘッダー情報(このデータは44.1kHzですよ、といった説明書き)」が含まれていないからです。
- 解決策:
- A案(推奨): 素直に「Cloud TTS API」を使い、設定で
audioEncoding: MP3を指定する。 - B案(技術者向け): Pythonなどでプログラムを書く際、44バイトのWAVヘッダーを自前で付与するか、
rawデータとしてパラメータ(24kHz, 16bit, monoなど)を指定して再生ソフトに読み込ませる。
- A案(推奨): 素直に「Cloud TTS API」を使い、設定で
落とし穴②:日本語特有の「バイト数制限」
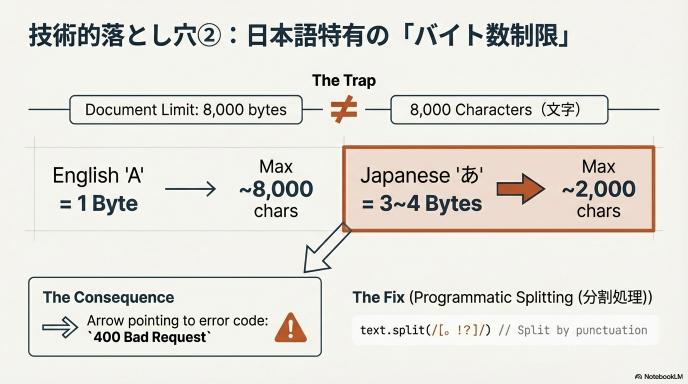
ドキュメントには「入力制限:テキストとプロンプト合わせて8,000バイト」と書かれています。
- 誤解: 「8,000文字も送れるのか、余裕だな」
- 現実: 英語は1文字1バイトですが、日本語(UTF-8)は1文字で3〜4バイト消費します。
- つまり、実質的な上限は約2,000〜2,500文字です。
- これを超えると
400 Bad Requestエラーで弾かれます。
- 回避策: 長文を読ませる場合は、必ずプログラム側で「句点(。)や改行」ごとにテキストを分割し、ループ処理でAPIを叩いて、最後に音声を結合する処理を組んでください。
落とし穴③:マルチスピーカーの「名前一致」
Gemini TTSは複数話者の掛け合いが可能ですが、設定がシビアです。
- 設定で
speaker_count: 2とし、それぞれの名前をRyoYukiと定義したとします。 - 入力テキスト内で
Ryu: こんにちはと書いてしまうと(oとuのタイポ)、エラーになるか、無視されてシングルスピーカーになります。 - プロンプト内の話者名と、設定上の話者名は、一言一句(大文字小文字含め)完全に一致させる必要があります。
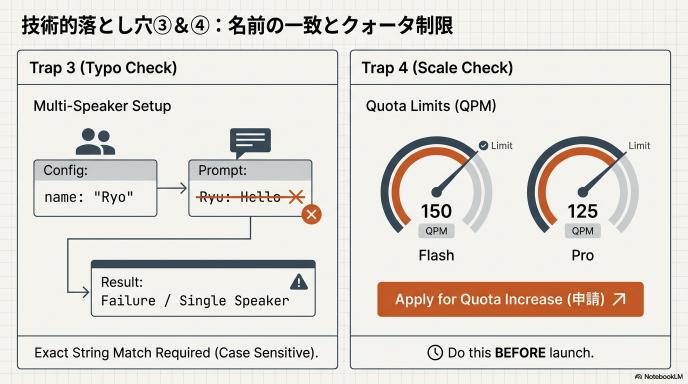
落とし穴④:レート制限(QPM)
デフォルトの制限(Quota)は意外と低いです。
gemini-2.5-flash-tts: 1分間に150リクエスト (150 QPM)gemini-2.5-pro-tts: 1分間に125リクエスト (125 QPM)ユーザー数が多いアプリを一気に公開すると、すぐに制限にかかります。本番公開前には必ずGoogle Cloudコンソールから「クォータの引き上げ申請」を行う必要があります。
第4章:AIを操る「魔法の言葉」プロンプト・ライブラリ

Gemini API(Aコース)を使う場合の、具体的な演出テクニックです。以下の言葉をプロンプトに混ぜるだけで、出力が激変します。
| 演出したい雰囲気 | 推奨プロンプト(キーワード) | AIの挙動 |
| 秘密の話 | whispering, softly, breathy tone, close to microphone | 吐息が混じり、音量が下がり、マイクに近い距離感が出る。 |
| 緊急事態 | urgent, panicked, fast pace, high tension | 早口になり、語気が強まり、間がなくなる。 |
| 昔話の語り | storytelling style, slow pace, soothing, warm voice | ゆっくりとしたテンポ、低めのトーン、抑揚が豊かになる。 |
| 冷徹なAI | robotic, monotone, flat, precise | 感情を意図的に排除し、一定のリズムで話す。 |
| ニュース | professional, broadcast style, clear enunciation, energetic | ハキハキとした発音、語尾が下がる断定的な口調。 |
【上級テクニック】
「怒って」と書くより、「信じていた親友に裏切られたことを知り、怒りで震えながら」とシチュエーションを書くほうが、AIはよりリアルな「演技」を行います。
第5章:お金の話(料金とコスト削減)
2026年2月時点の料金体系は「入力」と「出力」のダブル課金です。
1. 料金の計算式(Developer API / Cloud共通の考え方)
- 入力(テキスト): 100万文字(トークン)あたり $0.50 〜 $1.00
- 出力(音声): 100万音声トークンあたり $10.00 〜 $20.00
※ここで重要なのが「音声トークン」という単位です。 公式ドキュメントによると、目安として「音声1秒 ≒ 25トークン」です。
2. 1分喋らせるといくら?(ざっくり試算)
1分間のナレーション(約300文字)を作成する場合:
- 音声の長さ:60秒
- 音声トークン数:60秒 × 25 = 1,500トークン
- Flashモデルの場合(単価$10/1M):
- 1,500 ÷ 1,000,000 × $10 = $0.015(約2.3円)
- Proモデルの場合(単価$20/1M):
- 1,500 ÷ 1,000,000 × $20 = $0.03(約4.6円)
「高い」と感じましたか? そこで使うのが「Batch API」です。
3. 半額以下になる「Batch API」
リアルタイム性が不要な場合(例:夜間に翌日の記事を音声化しておく等)、Batch APIを使うと、これらの料金が50%オフになります。大量生成するメディア運営などの場合は、Batch一択です。

最終章:あなたへのアクションプラン
この長文を読み終えたあなたが、今すぐやるべきことは以下の通りです。
- AI Studioを開く: まずはGemini API(Aコース)で、プロンプトによる「演技の変化」を体感してください。コードを書く必要はありません。
- Flashモデルから始める: いきなりProを使わず、安価で高速なFlashモデルでテストしてください。最近のFlashは十分に高品質です。
- 「用途」を再確認する:
- アプリに組み込む → Cloud TTS API(MP3指定)
- 動画素材を作る → AI StudioでWAVダウンロード
- AIと会話する → Live API
Gemini TTSは、単なるツールではなく「表現のパートナー」です。仕様の壁さえ乗り越えれば、あなたのコンテンツに「声の命」を吹き込む最強の武器となるでしょう。
コメント