
「SunoやUdioは素晴らしいが、クラウド依存やクレジット制限が気になる」「制作ワークフローにAIを完全に組み込みたい」——そんなクリエイターやエンジニアにとって、決定版とも言えるオープンソースの音楽生成AIが登場しました。
2026年2月、ACE Studioチームが公開した「ACE-Step 1.5(ACE-Step v1.5)」です。
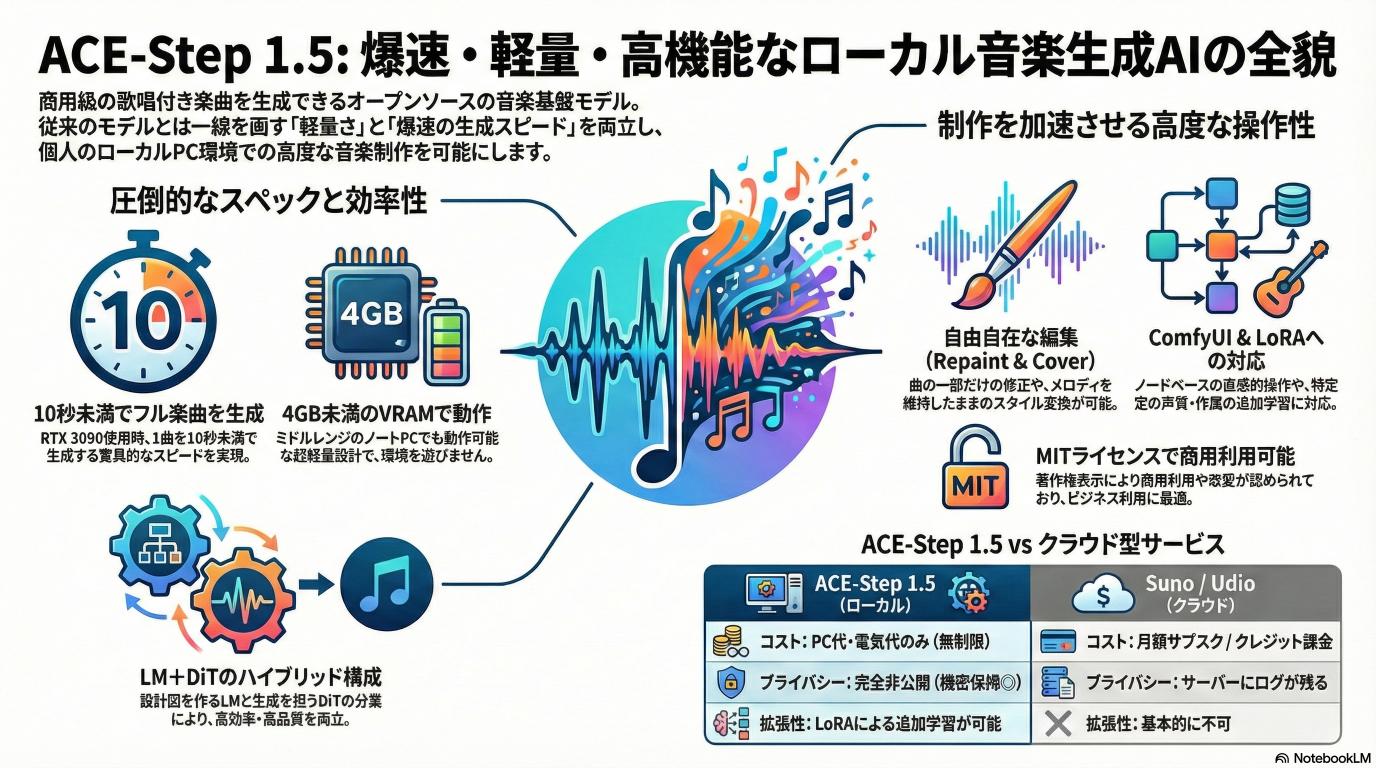
最大の特徴は、「商用級の歌唱付き楽曲」を「ローカルPC(VRAM 4GB未満)」で、「爆速」で生成できる点にあります。これまでのローカル音楽生成モデルは「重い・遅い・品質が低い」のいずれかを抱えていましたが、ACE-Step 1.5はその壁を破壊しました。
本記事では、技術仕様からComfyUIでの運用、LoRAによる追加学習まで、ACE-Step 1.5の全貌を徹底解説します。
音声のみはこちら↓
ACE-Step 1.5(ACE-Step v1.5)とは

概要:オープンソースの音楽生成基盤モデル
ACE-Step 1.5は、テキストプロンプトから歌唱付き音楽を生成する「Music Foundation Model(音楽基盤モデル)」です。
特筆すべきは、研究室レベルのスーパーコンピュータではなく、一般的なコンシューマー向けハードウェア(Consumer Hardware)での動作を前提に設計されている点です。
現在、プロジェクトは以下のリソースをフルオープンにしています(MITライセンス)。
- コード: GitHubにて公開(推論・学習コード含む)
- モデルの重み: Hugging Faceにて配布
- デモ: Hugging Face Spaces等ですぐに試用可能

「v1.5」で何が変わったのか?(革命的な進化点)
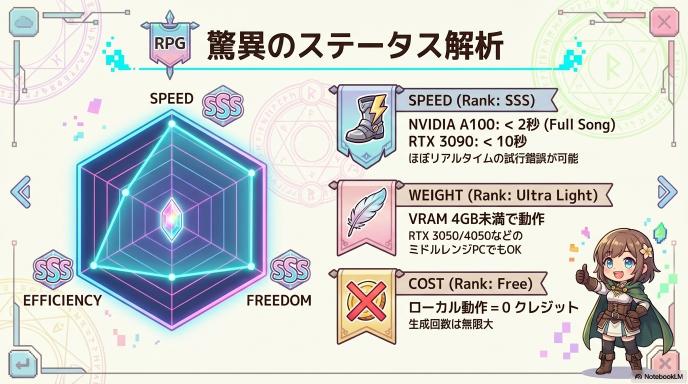
前バージョンからの最大の変更点は、生成速度とリソース効率の劇的な向上です。公式レポートによるスペックは以下の通りです。
- 圧倒的な生成速度:
- NVIDIA A100使用時:フルソングの生成が2秒未満
- RTX 3090使用時:10秒未満
- これは従来のモデルと比較しても桁違いの速さであり、ほぼリアルタイムに近い感覚で試行錯誤が可能です。
- 超軽量設計:
- モデル構造の最適化により、4GB未満のVRAMでもローカル動作が可能と謳われています。これはRTX 3050/4050搭載のノートPCなど、ミドルレンジの環境でも動作することを意味します。
- 制御性の向上:
- 歌詞(Lyrics)、タグ(Tags)、そして強力な編集機能が統合され、ガチャ要素(運任せ)を減らした「意図的な制作」が可能になりました。
ACE-Step 1.5で「できること」機能詳解(ユーザー視点)

テキスト→楽曲生成(歌唱あり/インスト)
基本機能はT2M(Text-to-Music)です。生成は主に以下の2要素で制御します。
- Tags(タグ): ジャンル、楽器編成、ムード、テンポなどを単語で指定します。
- 例:
J-pop, female vocals, energetic, piano intro, 120bpm
- 例:
- Lyrics(歌詞): 生成させたい歌詞を入力します。ボーカルなしのインスト曲(Instrumental)を作りたい場合は、歌詞欄を空にするか
instrumentalタグを使用します。
生成時間・尺の自由度
生成できる楽曲の尺は10秒〜10分という広範囲をカバーしています。
また、制作現場で重宝するのが「バッチ生成」機能です。一度に最大8曲のバリエーションを並列生成できるため、気に入るフレーズが出るまで効率よく「ガチャを回す」ことができます。

強力な編集ワークフロー(差別化ポイント)
SunoなどのWebサービスでは難しい、DAWのような微調整機能がAI側でサポートされています。
- Cover(再解釈): 既存の楽曲を入力し、メロディラインを維持したまま別のスタイル(例:ロック→ジャズ)に変換します。
- Repaint(インペイント): 曲の一部(特定の小節やミスした箇所)だけを指定して作り直し、前後と自然に繋げます。「Aメロは完璧だがサビだけ変えたい」といった場合に有効です。
- Vocal-to-BGM conversion: ボーカル曲から伴奏のみを生成、あるいはその逆といった操作もサポートされています。
多言語対応
公式発表では50以上の言語に対応しています。
日本語の歌唱生成も可能ですが、現時点でのデモや検証報告によると、英語に比べて発音やアクセントに多少の「AI特有の癖」が出る場合があります。ただし、これは後述するLoRAやプロンプトの工夫で改善が見込める領域です。
なぜ速くて軽いのか?技術的な仕組み

なぜ低スペックPCでもこれほど動くのか、その裏側にある技術(Technical Architecture)を簡単に解説します。
ハイブリッド構成:LM(設計図)+DiT(生成)
モデルの内部は大きく2つの役割に分業化されています。
- Language Model (LM):
- ユーザーの指示(歌詞やタグ)を解釈し、曲全体の「設計図(セマンティック・トークン)」を作成するプランナーの役割です。ここで曲の構成が決まります。
- Diffusion Transformer (DiT):
- LMが作った設計図に従って、実際に高解像度な音響データを生成するエンジニアの役割です。
この「プランニング」と「レンダリング」を分けることで、最初から全ての音データを計算する無駄を省き、効率化を実現しています。
独自のアライメント手法(内製RL)
従来のモデルが依存しがちだった「外部の報酬モデル(人間の好み判定用モデル)」を使用せず、内部的な強化学習(Internal RL)によってモデルの挙動を調整しています。
これにより、モデルサイズを肥大化させずに、「歌詞のタイミングを守る」「指定したジャンルに従う」といった指示追従性を高めています。
使い方:デモからローカル構築まで
まず試す:公式デモ(Hugging Face Spaces)
環境構築不要で、まずは実力を試したい方はHugging Faceのデモページへアクセスしてください。
ここではGPUリソースが共有されているため待機時間が発生しますが、プロンプトへの反応や音質を確認するには十分です。
ローカル実行:GitHub導入手順の全体像
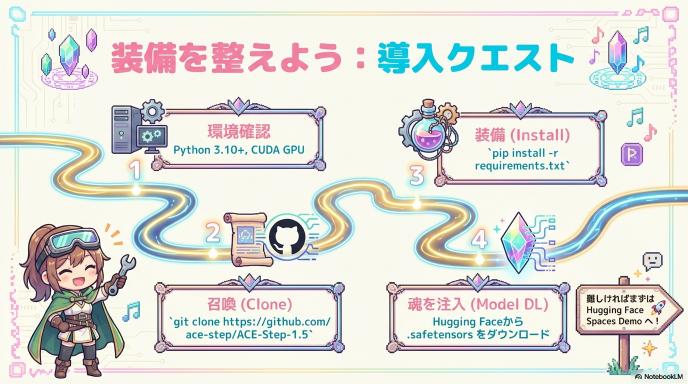
本格的に使い倒すにはローカル環境へのインストールが推奨されます。
- 環境要件: Python 3.10以上、CUDA対応GPU(NVIDIA製推奨)。
- インストール: GitHubリポジトリをクローンし、
requirements.txtから依存ライブラリをインストールします。Bashgit clone https://github.com/ace-step/ACE-Step-1.5 pip install -r requirements.txt - モデルDL: Hugging Faceからモデルの重みファイル(
.safetensors等)をダウンロードし、所定のフォルダに配置します。 - 実行: 提供されている推論用スクリプト(例:
inference.py)を実行します。
※初回セットアップ時は数GB単位のモデルダウンロードが発生するため、ディスク容量には余裕を持たせてください。
ComfyUIで使う(制作フローへの統合)
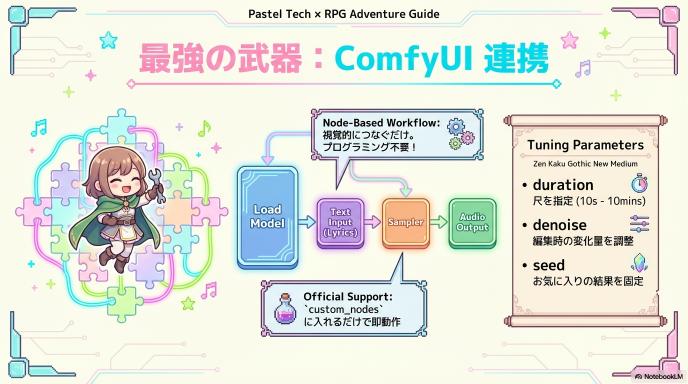
画像生成AIで普及しているノードベースUI「ComfyUI」にも正式対応しました。これが本モデルの実用性を大きく高めています。
- メリット: 直感的なノード接続で、「歌詞入力」「スタイル指定」「生成」「編集」をパイプライン化できます。
- 導入方法: ComfyUIの
custom_nodesフォルダにACE-Step用のファイルを追加し、配布されているワークフロー(JSON)を読み込むだけで動作します。 - 調整の勘所:
duration(長さ):秒数指定で長さをコントロール。denoise(ノイズ除去強度):Repaint時に元の曲をどれくらい残すかの調整値。seed(シード値):気に入った結果を固定して微調整する際に使用。
LoRAで「自分の作風」に寄せる(パーソナライズ)

ACE-Step 1.5の強力な機能の一つが、LoRA(Low-Rank Adaptation)への対応です。
これは、ベースモデルに対して「少量の追加データ」を学習させ、特定の画風ならぬ「曲風」や「声質」を覚えさせる技術です。
- 必要なデータ: 数曲〜数十曲程度の音声データがあれば学習可能とされています。
- 用途:
- 特定のジャンル(例:8bitゲーム音楽風、演歌風)への特化
- 特定のボーカルのニュアンスに寄せる
- 特定の楽器(例:三味線、アナログシンセ)の音色を強化する
※注意:LoRAの作成にはGPUメモリ(VRAM)が推論時よりも多く必要になる場合があります(通常12GB〜24GB推奨)。
ライセンス・商用利用・注意点
ライセンス:MIT License
公式リポジトリおよびモデルカードには、オープンソースライセンスの中でも非常に制約の少ない「MIT License」が適用されています。
これは基本的に、著作権表示を行えば「商用利用」「改変」「再配布」が可能であることを意味します。企業のR&D部門やアプリ開発者にとって非常に扱いやすいライセンスです。
生成物の取り扱いと権利(実務的注意)
ツール自体がMITライセンスであっても、生成されたコンテンツの権利や利用方法には注意が必要です。
- 既存曲のCover機能: 著作権のある曲を入力して変換した場合、依拠性が残り、著作権侵害となる可能性があります。
- LoRAによる模倣: 特定の有名アーティストの声を意図的に模倣するLoRAを作成・使用することは、パブリシティ権の侵害等に問われるリスクがあります。
「AIが作ったから免責される」ではなく、「入力データや学習データに権利侵害がないか」を常に確認する運用ルールが必要です。
他の音楽生成AIと何が違う?(比較)

SunoやUdioなどのクラウド型サービスと比較した場合の立ち位置です。
| 比較軸 | ACE-Step 1.5 (Local) | Suno / Udio (Cloud) |
| 実行環境 | ローカルPC (要GPU) | Webブラウザ (PC/スマホ) |
| コスト | PC代・電気代のみ (生成し放題) | 月額サブスク / クレジット課金 |
| プライバシー | 完全非公開 (機密保持◎) | サーバーにログが残る |
| 編集自由度 | ComfyUIやコードで完全制御 | サービス提供機能に限定 |
| 拡張性 (LoRA) | 自作データで追加学習可能 | 基本的に不可 |
| 音質・一貫性 | 調整次第 (ユーザーの腕による) | 安定して高品質 |
「手軽さ」ならクラウドですが、「機密保持」「コストパフォーマンス」「改造の自由度」ではACE-Step 1.5に圧倒的な軍配が上がります。

どんな人におすすめ?ユースケース

ACE-Step 1.5は以下のようなユーザー・用途に最適です。
- YouTuber・配信者:
- 動画の雰囲気に完璧に合わせた著作権フリーのBGMを量産する。
- ゲーム・映像クリエイター:
- 開発中の仮素材(プレースホルダー)として、大量のSEやBGMを即座に用意する。
- 作曲家・アレンジャー:
- アイデア出し(壁打ち)相手として。Repaint機能を使って「サビの別パターン」をAIに提案させる。
- AI研究者・エンジニア:
- LLMと同様に、音楽生成モデルのファインチューニングや構造解析を行うベースモデルとして。
実践Tips:
いきなりフル尺を作るのではなく、「90〜120秒」程度でドラフトを生成し、気に入ったシード値を使って尺を伸ばしたり、Repaintで修正したりするフローが最も効率的です。
FAQ(よくある質問)
Q. 必要なPCスペックは?VRAM 4GB未満でも本当に動く?
A. 公式発表ではVRAM 4GB未満での動作がサポートされています(量子化モデル等の利用を想定)。ただし、快適な生成(特にバッチ生成や学習)を行うには、VRAM 8GB〜12GB以上のRTX 3060/4060クラス以上が推奨されます。
Q. 歌詞は日本語でもOK?
A. 可能ですが、英語に比べるとリズムの乗り方や発音に違和感が出ることがあります。歌詞をローマ字で入力したり、プロンプトでJ-popタグを強調するなどの工夫で改善する場合があります。今後の日本語特化LoRAの登場も待たれます。
Q. 商用利用できる?
A. MITライセンスのため、モデルの利用自体は商用可能です。ただし生成物が「既存の著作物に似ていないか」など、最終的なコンテンツの権利確認はユーザーの責任となります。
Q. ComfyUIで何ができる?
A. 公式配布のワークフローを使えば、テキストからの生成はもちろん、Inpainting(部分修正)やAudio-to-Audio(オーディオ変換)も視覚的に構築可能です。プログラミング不要で高度な操作ができます。
Q. LoRAは何が嬉しい?
A. 「自分好みのドラムの音」や「特定のシンセサウンド」など、ベースモデルが持っていない、あるいは出しにくい音色をピンポイントで生成できるようになります。
まとめ

ACE-Step 1.5は、これまで巨大企業のマシンパワーが必要だった音楽生成を、個人のPCの中に解放する画期的なモデルです。
- ローカルで完結するセキュリティとコストメリット
- VRAM 4GBから動く軽量性
- ComfyUIやLoRAによる無限の拡張性
これらは、単なる「自動作曲ツール」を超え、クリエイターの新しい「楽器」となる可能性を秘めています。まずはHugging Faceのデモ、そしてComfyUIでのローカル生成をぜひ体験してみてください。
コメント