
2026年2月11日、中国のAIスタートアップ Zhipu AI(現Z.ai)が新たなフラッグシップモデル GLM-5 を公開しました。Reutersをはじめとする主要メディアが即座に報じたこのモデルは、「コード生成の先」を見据えた長期実行エージェントタスクへの対応を前面に打ち出しています。
本記事では、公式ドキュメント・Hugging Face・GitHubなどの一次情報を中心に、GLM-5の全体像を整理します。

音声のみはこちら↓
GLM-5の概要|何が「新しい」のか
GLM-5が従来モデルと一線を画すのは、その設計思想にあります。単なるコード生成や質問応答の精度向上ではなく、長期実行のエージェントタスク(long-horizon agentic tasks) や 複雑なシステムエンジニアリングを主戦場として明確に据えている点が最大の特徴です。
提供形態は、商用API(Z.ai)とオープンウェイト(MIT License)のハイブリッド。商用利用と研究コミュニティの両方に門戸を開く戦略を取っています。
技術面では、以下の3つが大きなトピックとして挙げられます。
- MoEで「総744B / アクティブ40B」という設計による計算効率と性能の両立
- DeepSeek Sparse Attention(DSA)統合による長文性能の維持とデプロイコストの削減
- 非同期RL基盤「slime」によるポストトレーニングの強化
公開タイムラインと経緯
報道・リリースの流れ
Reutersが2026年2月11日に「Zhipu AIがGLM-5を公開、オープンソースモデル」と報道したのが公開の起点です。翌12日にはGitHub上の zai-org アカウントでリポジトリが更新され、Hugging Face にも zai-org/GLM-5 としてモデルカードが公開されました。
Z.ai(旧Zhipu AI)は、GLM-4シリーズで中国AI市場における存在感を高めてきましたが、GLM-5では「オープンウェイト+商用API」の二段構えで、グローバル市場での競争力を一段引き上げる狙いが見て取れます。
主要スペック
パラメータ規模

GLM-5のパラメータ構成は以下のとおりです。
- 総パラメータ:744B(7,440億)
- 推論時アクティブパラメータ:40B(400億)
前世代の GLM-4.5(総355B / アクティブ32B)から大幅に拡大しており、MoEアーキテクチャの恩恵で、巨大な総パラメータ数にもかかわらず実際の推論コストは抑えられる設計です。
コンテキスト長と生成トークン数

- コンテキスト長:200K トークン
- 最大生成長:131,072 トークン(Hugging Face上の評価条件記述にて明示)
長大なコードベースや複雑なドキュメントを丸ごと扱えるだけの入力容量を持ちつつ、出力側も十分な長さを確保しています。
事前学習データ
事前学習データは 23Tトークンから28.5Tトークンへ増加しており、学習基盤の厚みが増しています。
アーキテクチャと技術的特徴
MoE(Mixture-of-Experts)アーキテクチャ
GLM-5は総744B・アクティブ40BのMoE構成を採用しています。MoEは入力に応じて一部の「専門家(Expert)」モジュールのみを活性化する仕組みで、全パラメータを常時使うDenseモデルと比べて、推論時の計算コストを大幅に抑えつつ、モデル全体としての知識容量を確保できます。
GLM-4.5からの拡大(355B/32B → 744B/40B)は、エキスパート数やエキスパートあたりのパラメータを増やすことで、特にエージェント系タスクでの「深い推論」を可能にしたものと考えられます。
DSA(DeepSeek Sparse Attention)統合

公式ドキュメントでは、DSA(DeepSeek Sparse Attention)を「初めて統合」したと明記されています。DSAはAttention計算をスパース化する手法で、長文処理時の計算量とメモリ消費を削減しつつ、性能劣化を最小限に抑えることを狙います。
GLM-5では、この統合により「長文性能を維持しつつデプロイコストを大幅に削減し、Token Efficiencyを改善した」と公式は主張しています。200Kトークンという大きなコンテキストウィンドウを実用的なコストで運用するための鍵となる技術です。
slime(非同期RL基盤)
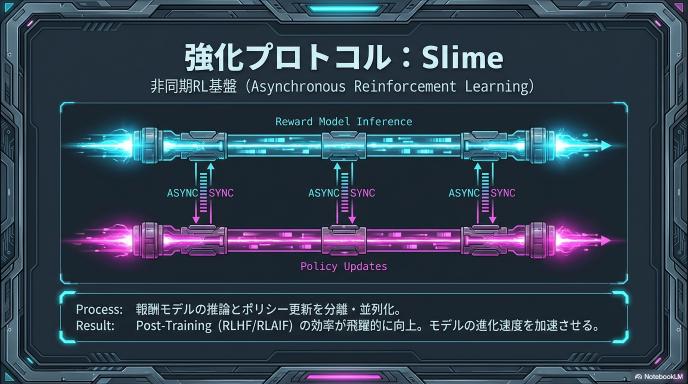
ポストトレーニング(RLHF / RLAIF 等の強化学習フェーズ)においては、独自開発の非同期RLインフラ「slime」が導入されています。公式ドキュメントとHugging Faceの双方で言及されており、ポストトレーニングのスループットと効率を改善するための基盤として位置づけられています。
非同期RLは、報酬モデルの推論やポリシーの更新を並列・非同期に実行することで、学習の待ち時間を削減し、大規模モデルのファインチューニング効率を高める手法です。
ベンチマーク結果の読み方

コーディング・エージェント系で強みを主張
GLM-5が最も強調しているベンチマーク結果は以下の2つです。
- SWE-bench Verified:77.8
- Terminal-Bench 2.0:56.2
公式はこれらを「オープンウェイト最上位級」と位置づけ、Claude Opus 4.5に匹敵するコーディング性能を主張しています。Hugging Faceのモデルカードには、推論・コーディング・ツール/エージェント系ベンチマークを横断した比較表が掲載されており、Claude Opus 4.5、Gemini 3 Pro、GPT-5.2などが比較対象として含まれています。

注意すべき点
一方で、MMLU等の古典的学術ベンチマークの体系的な提示が薄いという指摘も出ています。GLM-5は「エージェント実行を含むソフトウェア工学系で前に出ている」という評価が最も妥当ですが、汎用的な知識・推論能力の全貌を把握するには、今後の第三者評価を待つ必要があるでしょう。
提供形態と価格
オープンウェイト(MIT License)
Hugging Face上で MIT License として公開されており、商用利用を含め非常に自由度の高いライセンスです。これは研究者や開発者にとって大きな魅力であり、中国発のLLMとしては積極的なオープン戦略と言えます。
API(Z.ai)

Z.aiの公式価格は 1Mトークンあたり 以下のとおりです。
- GLM-5:Input $1 / Output $3.2
- GLM-5-Code:Input $1.2 / Output $5
Cached Input等の割引項目も用意されており、大量利用時のコスト最適化も考慮されています。Claude Opus 4.5やGPT-5.2と比較すると、かなり競争力のある価格設定です。
ローカル実行
OllamaのライブラリにもGLM-5が掲載されており、ローカル環境での実行導線が整備されつつあります。MoEアーキテクチャのため総パラメータは744Bと巨大ですが、アクティブ40Bという設計のおかげで、ハイエンドGPU環境であれば個人開発者でも動作させることが視野に入ります。
ハードウェアと地政学的文脈
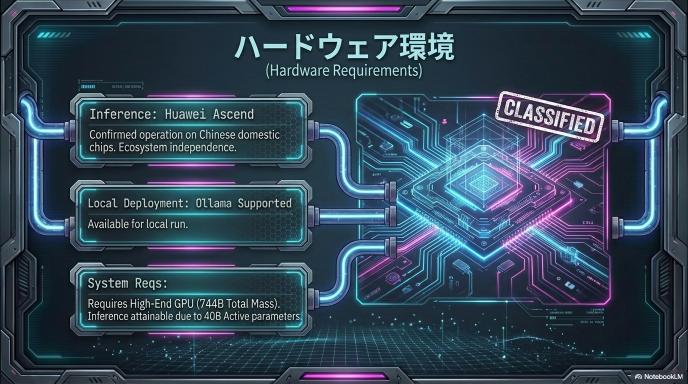
国産チップでの推論
Reutersの報道によれば、GLM-5は Huawei Ascendを含む中国国産チップで推論されるとのことです。Moore Threads、Cambricon(寒武紀)、Kunlunxin(崑崙芯)にも言及されており、米中間の半導体規制が続くなかでの「国産チップエコシステムでの自立」を示す動きとして注目されます。
学習環境については不明点も
一方、「学習までAscend/MindSporeで完結している」といった詳細については、一次情報で明確に確認できない部分もあります。推論環境は国産チップ(Reuters報道)、学習環境の詳細は公式が完全には開示していない──という認識が現時点では正確です。
仕様の「ブレ」に関する注意

一部の日本語二次記事で「745億パラメータ(=74.5B)/ 推論時44億」など、桁が異なる数値が流通しているケースが確認されています。
しかし、公式ドキュメント・Hugging Face・分析レポートのいずれにおいても、中核の数値は 総744B / アクティブ40B です。情報を引用・参照する際は、一次情報に基づく数値を優先することを強くお勧めします。
まとめ|GLM-5の位置づけと今後の注目点

GLM-5は、MoEアーキテクチャの大規模化、DSAによる長文処理の効率化、非同期RLによるポストトレーニング強化という三本柱で、「エージェント時代のフラッグシップ」を目指すモデルです。
SWE-bench VerifiedやTerminal-Benchでの高スコアは、ソフトウェア工学系タスクにおけるオープンウェイトモデルとしてのポジション確立を強く意識したものと言えます。MIT Licenseでのオープンウェイト公開と、競争力のあるAPI価格設定は、DeepSeek・Qwen・Kimiなど中国発LLM勢との差別化要因にもなり得ます。
今後は、第三者による汎用ベンチマーク評価の蓄積、国産チップ環境での実用的な推論性能、そしてエージェントフレームワークとの統合事例に注目が集まるでしょう。
コメント