
「AI音声は不自然で使えない」——その常識が崩れ始めています。
2026年4月15日に登場した「Gemini 3.1 Flash TTS」は、“用意された声を選ぶ”時代から、“声の演技を細かく指示する”時代へと進化を遂げた新世代の音声生成AIです。
この記事では、Googleの公式情報を軸に、その驚きの機能から具体的な料金、そして「結局どこまで実用的に使えるのか?」というリアルな判断材料までを徹底的に解説します。
Gemini 3.1 Flash TTSとは?“読み上げ”から“演技”へ変わった音声AI

これまで、テキストを音声にする技術(Text-to-Speech、略してTTS)は、どうしても「ロボットが原稿を読んでいる感」が拭えませんでした。しかし、Gemini 3.1 Flash TTSは、その壁を大きく越えようとしています。単なる文字の読み上げではなく、感情やニュアンスを含んだ「演技」ができるAIへと進化したのです。

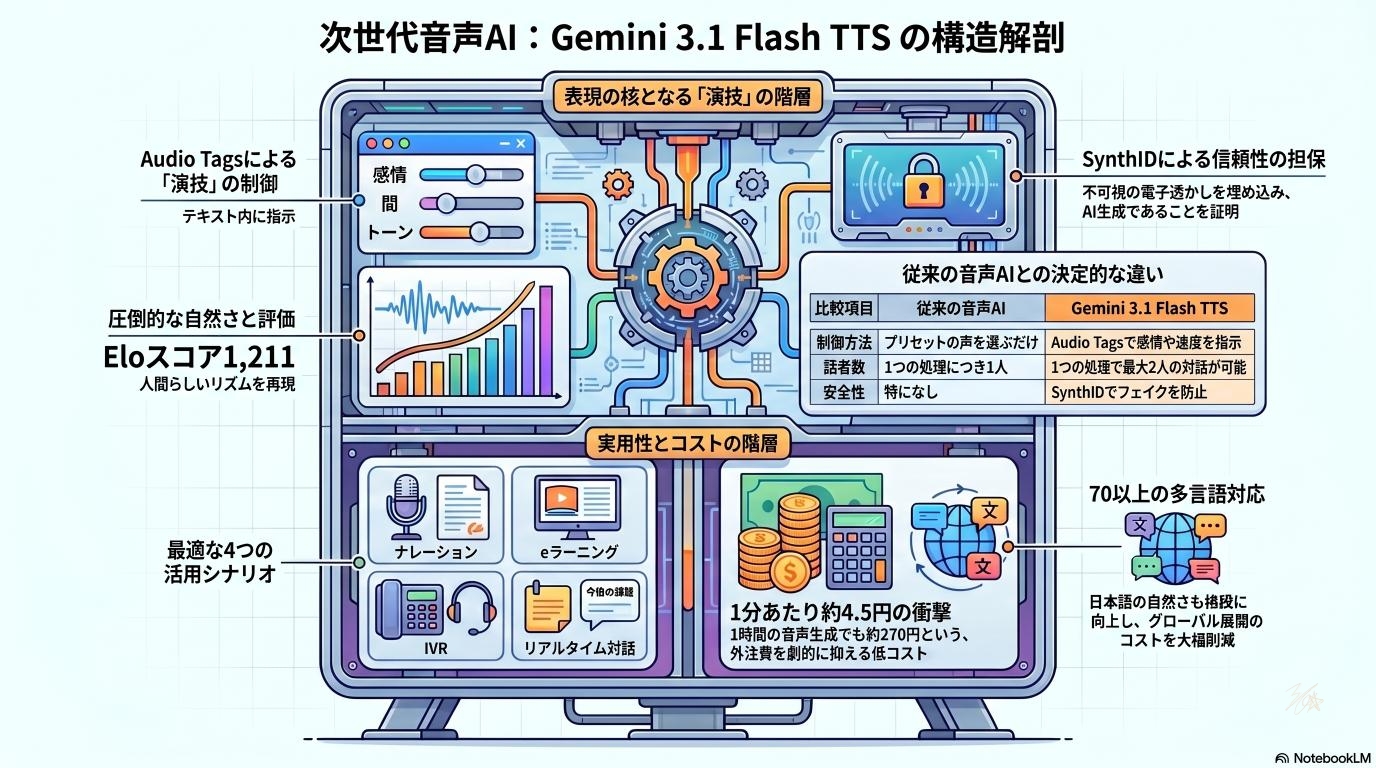
従来の音声AIとの決定的な違い
従来の音声AIは、「明るい声」「落ち着いた声」といったざっくりとしたプリセットから選ぶのが基本でした。しかし、Gemini 3.1 Flash TTSでは、テキストと一緒に「どう読んでほしいか」を詳細に指示できます。まるで人間のナレーターに直接お願いするように、細かなニュアンスを伝えることができるようになりました。
なぜ「自然さ」が一気に向上したのか
Googleの最新技術が詰め込まれたこのモデルは、品質を評価する独立系のベンチマークテスト「Artificial Analysis」のTTSリーダーボードでも非常に高い評価(Eloスコア 1,211)を獲得しています。文脈を深く理解する力がアップしたため、文末の自然な下がり方や、言葉と言葉の間の取り方など、人間が話す時の自然なリズムを再現できるようになりました。
対応サービス(API / AI Studio / Vertex AI)
この新しい音声AIは、すでに様々な場所で展開されています。開発者向けの「Gemini API」や「Google AI Studio」、企業向けの「Vertex AI」といったGoogleのプラットフォームのほか、動画制作ツールの「Google Vids」にも組み込まれています。身近なツールで、すぐにこの高品質な音声を体験できる環境が整っています。
最大の進化はここ|Audio Tagsで“声を演出できる”時代へ

Gemini 3.1 Flash TTSを語る上で絶対に外せないのが、「Audio Tags(オーディオタグ)」という新機能です。これこそが、AIをただの読み上げマシーンから「表現者」へと変えた最大の要因です。
「丁寧に」「ゆっくり」で本当に変わるのか?
例えば、同じ「ありがとうございました」という言葉でも、Audio Tagsを使って「深く感謝するように」「少し急ぎ足で」と指示を加えるだけで、出力される音声のトーンがガラリと変わります。自然言語でのスタイル制御を受け付けてくれるため、専門的なプログラムの知識がなくても、直感的に声をコントロールできます。
感情・間・トーンを操る仕組み
Audio Tagsを使うと、「ここは強調して」「ここで2秒の間(ポーズ)を入れて」「もっと悲しそうに」といった指示を、テキストの途中にピンポイントで挟み込むことができます。これにより、単調になりがちな長文のナレーションでも、最後まで聞き手を飽きさせない豊かな表現が可能になります。また、最大2人の声(マルチスピーカー)を掛け合わせることもできるため、対話形式の音声も作成可能です。
開発者が“音声ディレクター”になるという発想
これまでは、狙った声を作るために何度もAIを出力し直す「ガチャ」のような作業が必要でした。しかし、Audio Tagsの登場によって、開発者やクリエイターは、まるで収録スタジオでナレーターに指示を出す「音声ディレクター」のような役割を担うことができるようになったのです。
どこまで使える?4つのシナリオで実力を検証
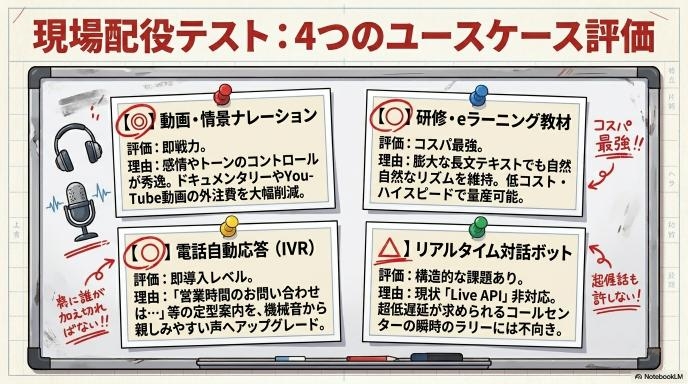
機能がすごいのはわかりましたが、一番気になるのは「実際のビジネスや現場で使えるレベルなのか?」という点ですよね。そこで、具体的な4つの利用シーンを想定して、実力を測ってみました。
①コールセンター対応 → リアルタイム運用はまだ厳しい
現在、超低遅延が求められる「Live API」には非対応となっています。そのため、顧客の言葉に即座に反応して音声を返すような、リアルタイムなコールセンターの自動対話システムを構築するには、まだ少し壁があります。今後のアップデートに期待したい分野です。
②情景ナレーション → ほぼ実用レベル
ドキュメンタリー映像やYouTube動画のナレーションとしては、驚くほど優秀です。Audio Tagsを使って「静かに」「盛り上げて」と演出を加えることで、プロのナレーターに肉薄するクオリティの音声を作成できます。外注コストの削減を考えるなら、即座に検討すべきレベルです。
③電話自動応答(IVR) → 即導入可能なクオリティ
「営業時間のお問い合わせは1を…」といった、決まった内容の音声を流す自動応答システムには最適です。従来の機械的で冷たい音声よりも、はるかに自然で親しみやすい案内ができるため、顧客のストレス軽減に直結します。
④研修・eラーニング → コスパ最強の選択肢
社内研修の動画やeラーニングの教材は、読み上げるテキスト量が膨大になりがちです。すべてをプロに依頼すると多額の費用と時間がかかりますが、このAIを使えば、高品質な読み上げ音声を低コストかつスピーディに量産できます。間違いなく「コスパ最強」の用途です。
実はここが重要|料金とコスト感をリアルに解説
「そんなに高機能なら、料金も高いのでは?」と思うかもしれませんが、実はコストパフォーマンスの良さもGemini 3.1 Flash TTSの大きな魅力です。公式の「Gemini Developer API」の価格(Pricing)をもとに、具体的なコスト感を紐解いてみましょう。
| 処理タイプ | テキスト入力(指示) | オーディオ出力(音声生成) | 特徴 |
| Standard | $1.00 / 100万トークン | $20.00 / 100万トークン | 通常のAPIリクエスト。即座に音声が欲しい場合。 |
| Batch API | $0.50 / 100万トークン | $10.00 / 100万トークン | 急ぎではない大量の処理向け。コストが半額に。 |
1分あたりいくら?具体的なコスト目安

Standard料金の場合、音声出力は「100万オーディオトークンあたり20.00ドル」です。公式ガイドには「1秒の音声=25オーディオトークン」と明記されているため、計算すると100万オーディオトークンは約11時間分の音声に相当します。 これを日本円に換算(1ドル=150円計算)すると、1時間の音声を生成してもたったの約270円、1分ならなんと約4.5円という破格の安さです。さらに、急ぎではない処理(Batch API)を使えば、その半額(出力100万トークンで10.00ドル)までコストを抑えられます。
無料で試せるGoogle AI Studioの強み
いきなりAPIで課金するのは不安という方は、Google AI Studioを使えば、一定の制限内で無料でモデルを試すことができます。ここで実際の日本語のアクセントや、Audio Tagsの効き具合をしっかり確かめてから、本格的な導入を判断できるのは非常に良心的です。
以前のモデルとの比較でどちらを選ぶべきか
テキスト生成のGeminiモデルとは用途が違いますが、もし音声データ(.wavなど)を生成・保存する目的であれば、品質とコストの圧倒的なバランスから見て、Gemini 3.1 Flash TTS(プレビュー版のモデルID:gemini-3.1-flash-tts-preview)を選ぶのが現在の最適解と言えるでしょう。
70言語対応は本当に強い?グローバル展開での可能性
Gemini 3.1 Flash TTSは、70以上の言語に対応していることも公式の大きなウリの一つです。これがビジネスにどのようなインパクトを与えるのか、詳しく見ていきましょう。
日本語の自然さはどこまで改善されたか
海外製の音声AIは、「流暢だけどどこか外国人が話す日本語っぽい」という弱点がよくありました。しかし、今回のモデルでは、日本語特有のイントネーションやアクセントの自然さが格段に向上しています。長時間でも違和感なく聴き続けられる実用的なレベルに達しています。
多言語ナレーションの実務インパクト
自社の製品紹介動画を、英語、中国語、スペイン語などに翻訳して世界中に配信したい場合。これまでなら各国のネイティブナレーターを手配する必要がありましたが、Gemini 3.1 Flash TTSなら、1つのプロンプトとテキストを用意するだけで、あっという間に多言語版の音声が完成します。
ローカライズコストが崩壊する未来

翻訳から音声吹き替えまでのプロセスがAIで完結するようになれば、海外展開にかかる「ローカライズ(現地語化)コスト」は劇的に下がります。資金力のある大企業だけでなく、中小企業や個人のクリエイターでも、世界市場を相手に気軽にコンテンツを発信できる時代がやってきたのです。
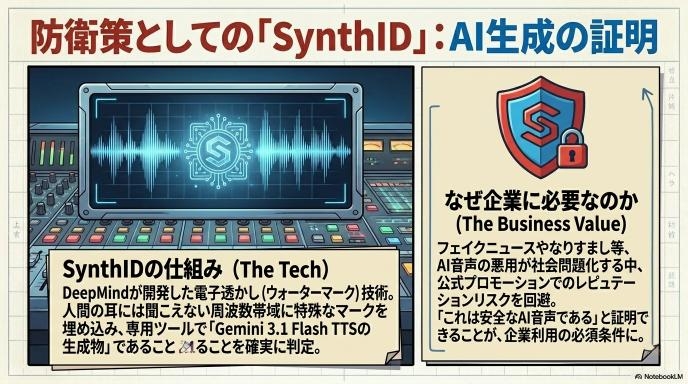
見逃せない新要素|SynthIDで“AI音声の証明”が入る時代
AIの性能が上がり、人間の声と区別がつかなくなるにつれて、新たな問題も生まれています。フェイク音声やなりすましを防ぐためのGoogleの解答が「SynthID(シンセアイディー)」です。
音声ウォーターマークとは何か
SynthIDは、生成された音声データの中に、人間の耳には聞こえない特殊な「電子透かし(ウォーターマーク)」を埋め込む技術です。これにより、専用のツールを使えば「この音声はAI(Gemini 3.1 Flash TTS)で作られたものである」と確実に判定することができます。
なぜ今「AI生成の証明」が重要なのか
著名人の声を無断で再現したフェイクニュースや、詐欺への悪用など、AI音声の影の部分が社会問題化しています。「これはAIが作った安全な音声ですよ」と明確に証明できる機能は、テクノロジーが社会に正しく受け入れられるために必要不可欠なものです。
企業利用でのリスク対策としての意味
企業が公式なプロモーション動画やサービスでAI音声を使う場合、後から「フェイクだ」「人間を騙している」と批判されるリスク(レピュテーションリスク)があります。SynthIDが組み込まれているモデルをあえて選ぶことは、企業としての責任と透明性を保つための重要な防衛策になります。
メリットだけじゃない|使う前に知るべき制約

ここまで素晴らしい機能を紹介してきましたが、もちろん万能ではありません。実際にプロジェクトへ導入する前に、押さえておくべき「現在の限界」も包み隠さずお伝えします。
リアルタイム用途に弱い理由
先ほども触れましたが、現在はリアルタイムでのやり取りに特化した「Live API」には非対応です。入力は最大8,192トークン、出力は最大16,384トークンと情報量の余裕はありますが、AIアシスタントとの瞬時の会話ラリーのような用途には、別のアーキテクチャを検討する必要があります。
出力形式・話者数の制限
API経由での音声保存は主に.wav形式が想定されています。また、1つの出力で同時に会話できるのは「最大2話者のマルチスピーカー」までです。3人、4人と入り乱れるような複雑なラジオドラマを一度に作るには、シーンを分けて音声編集ソフトで結合するなどの工夫が必要です。
Preview段階ゆえの注意点
モデル名が gemini-3.1-flash-tts-preview となっている通り、現在はまだプレビュー段階です。今後、仕様の変更や、生成される音声の質感が微調整される可能性もゼロではありません。本番環境に組み込む際は、公式のChangelog(アップデート情報)を定期的にチェックする体制が必要です。
結論|Gemini 3.1 Flash TTSは「どんな人が使うべきか」

それでは最後に、この驚くべき進化を遂げた音声AIを、今すぐ使うべき人と、そうでない人を整理してみましょう。
今すぐ導入すべきケース
動画クリエイター、社内研修の担当者、IVR(自動音声応答)の構築者には、文句なしにおすすめです。Audio Tagsによる表現力の高さと、1時間の音声が約270円という圧倒的なコストパフォーマンスは、これまでの作業時間を大幅に削減し、コンテンツのクオリティを底上げしてくれます。
まだ様子見でもいいケース
1秒の遅れも許されないリアルタイムな音声対話システムを作りたい方や、3人以上の複雑な掛け合いをAIの1回の出力だけで完結させたい方は、まだ少し待つか、他のシステムとの併用を考える必要があります。
今後の進化で起きること
「用意された声を選ぶ」から「演技を細かく指示する」へのパラダイムシフトは、まだ始まったばかりです。Googleは今後もこの分野に注力していくでしょう。今のうちからGemini 3.1 Flash TTSに触れ、AIを「ディレクションする」感覚を掴んでおくことは、これからのコンテンツ制作において強力な武器になるはずです。ぜひ、実際にその耳で新時代のAI音声を確かめてみてください。
参考元一覧
【公式・一次情報】
- Google公式ブログ(Gemini 3.1 Flash TTS発表) https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-tts/
- Gemini API Docs:3.1 Flash TTS Preview モデル情報 https://ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-tts-preview
- Gemini API Docs:音声生成ガイド https://ai.google.dev/gemini-api/docs/speech-generation
- Gemini API 料金体系(Pricing) https://ai.google.dev/gemini-api/docs/pricing
- Gemini API Changelog https://ai.google.dev/gemini-api/docs/changelog
- Google Cloud ブログ(Vertex AI展開) https://cloud.google.com/blog/products/ai-machine-learning/gemini-3-1-flash-tts-on-google-cloud
- Vertex AI Docs:Text-to-Speech https://docs.cloud.google.com/vertex-ai/generative-ai/docs/speech/text-to-speech
- Google Workspace Updates(Google Vidsへの統合) https://workspaceupdates.googleblog.com/2026/04/new-more-expressive-ai-voiceovers-in-Google-Vids-and-16-additional-languages-powered-by-Gemini-3.1-Flash-TTS.html
- DeepMind:SynthID(音声ウォーターマーク技術) https://deepmind.google/models/synthid/
- Gemini API:SynthIDによるセーフガード https://ai.google.dev/responsible/docs/safeguards/synthid
【品質評価・ベンチマーク】
- Artificial Analysis:Text-to-Speech リーダーボード https://artificialanalysis.ai/text-to-speech/leaderboard
- Artificial Analysis:モデル詳細 https://artificialanalysis.ai/text-to-speech/models
【日本語の補助解説】
- note:npaka氏による要約記事 https://note.com/npaka/n/n697be937e07e
- 技術評論社:Gemini 3.1 Flash TTS解説記事 https://gihyo.jp/article/2026/04/gemini-3-1-flash-tts
コメント