
「今の画像生成AI、ここまでできるようになったのか……」 ここ数日、X(旧Twitter)のタイムラインを眺めていて、思わずスクロールする手を止めた人も多いのではないでしょうか。
架空のアニメ映画のポスター、感情豊かなロボットのイラスト、さらにはセリフ付きの4コマ漫画や、CMの絵コンテまで。これらはすべて、ある一つの新しいAIモデルによって一瞬で生成されたものです。
その正体は、OpenAIが発表した「ChatGPT Images 2.0」。
ただ「綺麗な絵が描ける」という次元を通り越し、私たちの仕事や創作活動にそのまま使えるレベルへと進化を遂げています。なぜここまで一気に注目を集めたのか。そして、これまでの画像生成AIと何が決定的に違うのか。話題沸騰の理由から、その裏にある確かな実力まで、順を追って分かりやすくひも解いていきます。

Xがざわついた。ChatGPT Images 2.0に視線が集まった理由

AIの新しい機能が発表されることは珍しくありませんが、今回の盛り上がり方は少し異質でした。一部のテクノロジー好きだけでなく、映像クリエイターやイラストレーター、ビジネスパーソンまでがこぞって驚きの声を上げていたのです。
OpenAIの投稿をきっかけに、一気に拡散
発端は、開発元であるOpenAIの公式アカウントによる一つの投稿でした。「ChatGPT Images 2.0のご紹介」という言葉とともに公開されたのは、複雑な視覚タスクをこなし、精密なビジュアルを作り出すAIの姿。よりシャープな編集ができ、豊かなレイアウトが組めるという発表は、瞬く間に世界中へ拡散されました。
ユーザー投稿が“性能の伝わる実例”になった
しかし、本当に話題を爆発させたのは一般ユーザーたちの投稿です。「たった一言の指示で、とんでもないクオリティのアニメポスターができた」「これまで自分がChatGPTをどう扱ってきたか、告発する4コマ漫画を作ってもらった」など、具体的な「使ってみた」という実例が次々とタイムラインに溢れました。
単なる新機能発表で終わらなかった背景
なぜこれほど実例が広まったのか。それは、このモデルが「遊び」だけでなく「実用」に耐えうるクオリティだったからです。公式の綺麗なデモ映像だけでなく、ユーザー自身が無茶ぶりをして、それにAIが完璧に応えてみせたことが、「これは本物だ」という熱狂を生み出しました。
まず押さえたい、ChatGPT Images 2.0とは何者か

「なんだか凄そう」という雰囲気は伝わってきますが、そもそも今回のアップデートはどういう位置づけのものなのでしょうか。名前がいくつか飛び交っているため、まずはここをすっきりと整理しておきましょう。
ChatGPT向けの新しい画像生成体験として登場
結論から言うと、これは「ChatGPT上で画像を生成する時の仕組み(モデル)が、最新で超強力なものに切り替わった」ということです。OpenAIの公式発表では『ChatGPT Images 2.0』という名称で華々しくデビューを飾りました。
APIのモデル名「gpt-image-2」との違い
少しややこしいのが、見る場所によって名前が少し違う点です。ChatGPT内のリリースノート(更新履歴)を見ると『ImageGen 2.0』と案内されています。さらに、開発者がプログラムに組み込むためのAPIのモデル名としては『gpt-image-2』という名前が付けられています。
名前が複数見えるからこそ、最初に整理しておきたいポイント
「ChatGPT Images 2.0」「ImageGen 2.0」「gpt-image-2」。これらはどれも、指している中身は同じ「最新の画像生成モデル」です。SNSやブログで情報収集をする時は、これらの名前が同じものを指していると覚えておくと、混乱せずに全体像を掴むことができます。
今回の進化は“きれいな画像”だけではない

これまでのAIも、十分に「きれいでリアルな画像」を作ることはできました。しかし、今回の進化の本当の凄さは「見栄えの良さ」よりも「指示への忠実さと実用性」にあります。
文字入り画像が崩れにくくなった
画像生成AIの長年の弱点だったのが「文字」です。看板やポスターに文字を入れようとすると、謎の象形文字のようになってしまうことがよくありました。今回のモデルは、画像の中に密度高く文字を配置する能力が劇的に向上しています。
複雑なレイアウトや構図の指示に強くなった
「右に赤い車を置いて、左上から光を当てて、背景はサイバーパンク風の街並みにして…」といった、人間でも頭を悩ませるような複雑なレイアウトや細かな構図の指示を、AIがしっかりと理解してくれるようになりました。
編集のしやすさが、実用性を一段押し上げた
画像の一部分だけを修正する「編集」の性能も格段に上がっています。一度作った画像の「ここだけ直して」という指示がシャープに反映されるため、最初から完璧な呪文(プロンプト)を唱えなくても、対話しながら理想の画像を作り上げることができます。
世界知識を踏まえた生成が、使い勝手を変える
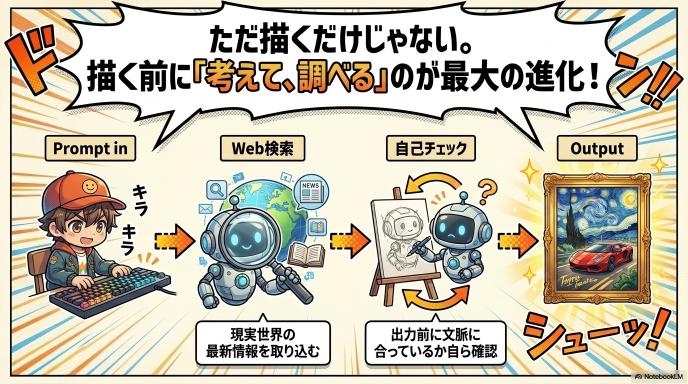
もう一つの目玉が「Thinking Mode(思考モード)」です。この機能を使うと、AIは画像を生成する前にWeb検索を行い、現実世界の最新情報を取り込みます。さらに生成前に自己チェックを行うため、より精度の高い、文脈に沿った画像を生み出すことができるのです。
なぜここまで評価されたのか。注目を集めた3つの強み
機能が向上したことは分かりましたが、それがなぜXでの大バズりに繋がったのでしょうか。ユーザーの心を掴んだ具体的な強みは大きく3つあります。
見た目の美しさだけでなく、指示への忠実さ
これまでのAIは、指示を少し無視してでも「AIが思う美しい絵」を描きがちでした。しかし今回は、ユーザーが指定した細かい条件(色、配置、雰囲気)を驚くほど忠実に守ります。この「言うことを聞いてくれる感」が、クリエイターたちのストレスを大きく軽減しました。
ポスター、漫画、資料画像までこなせる守備範囲の広さ
風景や人物だけでなく、文字とイラストが混ざった「映画のポスター」、コマ割りされた「漫画」、さらには「企画書の概念図」まで。一つのモデルでこなせる出力形式のバリエーションが圧倒的に広がり、多様なニーズに応えられるようになりました。
思いつきの遊びから、仕事の試作までつながる汎用性
「こんなロボットがいたら面白いな」という遊びの生成から、「明日の会議で使うCMの絵コンテを作ろう」というガチの業務までシームレスに繋がります。プロ・アマ問わず、誰にとっても「使える」ツールになったことが、高く評価されている理由です。
Arena首位が意味するもの
このモデルの実力は、ユーザーの体感だけでなく、客観的なデータでも証明されています。AIの性能を競う世界的なベンチマークにおいて、歴史的なスコアを叩き出しました。
ベンチマークで高評価を得たインパクト

AIの性能を評価する有名なプラットフォーム「Arena.ai」において、gpt-image-2はすべての画像部門で1位の座を獲得しました(2026年4月22日時点)。「Text-to-Image」部門ではスコア1512点を記録し、2位に242点という過去最大の差をつけての完全勝利です。
数字が示す強さと、実利用で見るべき視点
ベンチマークの点数が高いということは、それだけ「人間が思い描いた通りのものを、一発で出してくれる確率が高い」ということを意味しています。何度も生成し直す手間が減るため、実務で使う際のタイムパフォーマンスが劇的に向上します。
ランキング1位だけで語り切れない部分もある
とはいえ、スコアだけが全てではありません。どんなに頭の良いAIでも、指示を出す人間の言葉がフワッとしていれば、期待通りのものは出てきません。1位という称号に頼りきるのではなく、AIのクセを理解して付き合っていく姿勢は引き続き必要です。
実際、誰に刺さるのか

ここまで進化した画像生成AI。もはや一部のエンジニアだけのおもちゃではありません。具体的にどんな人の強い武器になるのでしょうか。
SNS投稿やブログのアイキャッチを作りたい人
文字入れに強くなったことで、ブログのトップ画像や、X、Instagramでの目を引く画像づくりが劇的に楽になります。「架空の映画ポスター風で」といった遊び心のある指定にも応えてくれるため、発信の幅が大きく広がります。
広告・動画・漫画のラフを素早く形にしたい人
「こんな感じの映像を作りたい」というアイデアが頭の中にあっても、それを他人に伝えるのは難しいものです。ChatGPT Images 2.0を使えば、プロンプトひとつで数カットの提案をしてくれるため、クリエイターの強力な右腕になります。
社内資料や提案書のビジュアル品質を上げたい人
パワーポイントの資料を作る際、「ちょうどいいフリー素材が見つからない」と悩んだ経験はないでしょうか。これからは、複雑な概念図や特定のシチュエーションを表現したイメージ画像を、自分の言葉で直接AIに作らせることができます。
日本語を含む画像表現に悩んできた人
これまで、画像内に日本語を入れようとすると不自然な形になることが多く、日本のユーザーにとっては大きな壁でした。今回、日本語のレンダリングが大幅に強化されたことで、ようやく「そのまま使える日本語入り画像」が手に入るようになりました。
盛り上がる今だからこそ、冷静に見ておきたい点
| 項目 | 詳細・特徴 | 備考 |
| 主な進化ポイント | ・高密度な文字の正確な描画(日本語対応の強化) ・複雑なレイアウトや構図への高い指示追従性 ・細かな編集(インペイント等)性能の向上 | これまで難しかった「ポスター」や「漫画のコマ割り」が実用レベルに。 |
| Thinking Mode | 生成前にWeb検索を行い、リアルタイムな情報を反映。AI自身が自己チェックをしてから画像を出力する機能。 | より文脈に合った、精度の高い画像が生成可能に。 |
| 解像度・サイズ | 柔軟なサイズ指定に対応(長辺最大3840px未満など)。 | ※2560×1440(2K)を超えるサイズは現時点では実験的(experimental)な扱い。 |
| 提供プラン(通常版) | すべてのChatGPTユーザー | ChatGPT内では「ImageGen 2.0」と表記されることも。 |
| 提供プラン(Thinking付) | Plus / Pro / Business プラン | Enterprise / Edu 向けも順次対応予定。 |
| APIモデル名 | gpt-image-2 | 開発者向けに提供。 |
タイムラインはお祭り騒ぎですが、実際に仕事や趣味で使い始める前に、いくつか冷静に把握しておきたい注意点もあります。
話題先行の情報は、名称や機能の混同が起きやすい
Xでバズっている生成例の中には、プロンプト(指示文)が極めて優秀なものや、何度も試行錯誤した結果の「奇跡の一枚」も含まれています。また、「2K対応!」と騒がれていても、公式では2K(2560×1440)を超えるサイズはまだ実験的(experimental)な扱いとされているなど、情報の独り歩きには注意が必要です。
提供プランや使える機能には差がある
とても魅力的な機能ですが、すべての人が全ての機能を無制限に使えるわけではありません。通常の「ChatGPT Images 2.0」は広く提供されていますが、より高度な推論やWeb検索を伴う「Thinking Mode」は、PlusやProなどの有料プランユーザーが中心となります。
ベンチマークの強さと、自分の用途との相性は別問題
Arenaでの圧倒的1位は事実ですが、AIにはそれぞれ「得意な画風」があります。自分が求めているのがアニメ調なのか、実写風なのか、水彩画なのかによって、他社のモデル(MidjourneyやNijijourneyなど)の方がしっくりくるケースも当然あります。

ChatGPT Images 2.0は、画像生成の“使いどころ”を広げた
きれいな女の子のイラストや、ファンタジーの風景を出力して「すごい!」と喜んでいた時代は、どうやら終わりを告げようとしています。
作品づくりだけでなく、実務に入り込んできた
今回のアップデートで最も重要なのは、AIが「作品づくりのツール」から「実務の強力なパートナー」へと完全にシフトしたことです。思い描いたレイアウト、必要な文字情報、そして世界観。それらを正確に形にする道具が、今、私たちの手元にあります。
これからは「作れるか」より「どう使うか」が問われる

画像が作れること自体は、もはや珍しいことではありません。これからの時代に問われるのは、「この優秀なアシスタントにどんな指示を出し、自分の仕事や生活にどう組み込んでいくか」という人間の想像力とディレクション能力です。
今回のアップデートが示した次の競争軸
ChatGPT Images 2.0が示したのは、画像生成AIの競争が「画質の良さ」から「人間といかにスムーズに連携できるか(知能・思考・編集力)」へ移ったということです。生成AIの体験が一段進んだ今、まずは一度、あなた自身の言葉でAIに画像をリクエストしてみてください。きっと、その精度の高さに驚くはずです。

参考元
- OpenAI公式発表 Introducing ChatGPT Images 2.0
- ChatGPT Release Notes(更新履歴) ChatGPT Release Notes
- ChatGPT Images FAQ(よくある質問) ChatGPT Images FAQ
- ChatGPT Images System Card(安全性やモデルの詳細) ChatGPT Images System Card
- GPT Image 2 モデルページ(開発者向け) GPT Image 2 Model Page
- Image generation guide(画像生成ガイド) Image generation guide
- Prompting guide / サイズ条件(プロンプトのコツ) Prompting guide
- Arena leaderboard(AIベンチマークランキング) Arena leaderboard
- Arena leaderboard changelog(ランキング更新履歴) Arena leaderboard changelog
コメント